データ分析の基礎から応用まで!前処理、モデル構築、適用を徹底解説
データ分析は、ビジネスや研究において不可欠のツールとなっています。膨大なデータを適切に処理し、有効なインサイトを導き出すためには、分析の基礎知識が必要不可避です。本稿では、データ分析の基本的な前処理から、モデル構築や適用まで、徹底的に解説します。初心者から経験者まで、データ分析の基礎をより深く理解し、より効果的な分析を実現するための指南を提供します。

データ分析の基礎から応用まで!前処理、モデル構築、適用を徹底解説
データ分析は、企業の意思決定や政策決定において非常に重要な役割を果たす技術です。データ分析の基礎から応用までを徹底解説し、実際にデータ分析を行うためのスキルを身に付けましょう。
データ前処理の重要性
データ分析の第一歩は、データの前処理です。データの前処理は、ノイズの除去、欠損値の補完、データの正規化などを行うことで、データの品質を高めます。データのクリーン니스は、モデル構築や適用の成否を左右します。
| 前処理の方法 | 説明 |
|---|---|
| ノイズの除去 | データ中に含まれるノイズを除去することで、データの信頼性を高める |
| 欠損値の補完 | 欠損している値を補完することで、データの完全性を高める |
| データの正規化 | データを正規化することで、モデル構築に適した形式にする |
モデル構築の基本
モデル構築は、データ分析の核心です。モデル構築では、機械学習や統計学の技術を用いて、データにhiddenのパターンや相関関係を見つけ出します。
| モデル構築の手法 | 説明 |
|---|---|
| 過去の経験則 | 過去の事例に基づいて、将来の予測を行う |
| 決定木 | 決定木を用いて、データの分類や予測を行う |
| 線形回帰 | 線形回帰を用いて、連続的な値の予測を行う |
モデルの評価と選択
モデル構築されたモデルを評価し、最適なモデルを選択するために、評価指標を用います。評価指標には、Accuracy、Precision、Recall、F1などがあります。
| 評価指標 | 説明 |
|---|---|
| Accuracy | モデルの予測結果が正しい割合 |
| Precision | モデルの予測結果が正しい場合の割合 |
| Recall | モデルの予測結果が正しい場合の割合 |
モデルの適用
モデル構築されたモデルを、実際の problemaに適用します。モデルの適用には、ビジネスプロセスの改善や、新しいビジネスチャネルの開拓など、多くの可能性があります。
| モデルの適用先 | 説明 |
|---|---|
| マーケティング | マーケティングでのターゲティングや、顧客の予測 |
| Operations | 製造やロジスティクスでのproduktionschedulingや、予測 |
| Finance | 金融でのリスクマネジメントや、ポートフォリオの最適化 |
データ分析の将来像
データ分析は、ますます進化していきます。AIやIoTの技術を組み合わせることで、より高度なデータ分析が可能になります。
データ分析における前処理とは?
データ分析における前処理とは、データを分析する前の準備段階でのデータの整備や調整を行うプロセスです。ノイズの除去、欠損値の補完、スケーリングなどを含み、データの品質向上や分析の正確さを高めることを目的としています。
前処理の महत性
データ分析では、前処理が適切に行われていないと、分析結果が不正確になる場合があります。ノイズや欠損値が含まれるデータを分析すると、結果が誤った値を示す可能性があります。また、スケーリング</strongexpoがない場合、数値の範囲が異なる変数同士を比較することができません。前処理を行うことで、これらの問題を解消し、正確な分析結果を得ることができます。
- ノイズ除去:離れた値や異常な値を除去することでデータの信頼性を高める。
- 欠損値補完:欠損している値を推定や補完することでデータの完全性を高める。
- スケーリング:数値の範囲を揃えることで異なる変数同士を比較することができる。
前処理の手法
前処理には様々な手法があります。機械学習や統計学に基づく手法や、データクリーニングなどの手法があります。各手法には異なる長所や短所があり、データの特性や分析の目的によって適切な手法を選択する必要があります。
- 機械学習:機械学習アルゴリズムを用いてノイズ除去やスケーリングを行う。
- 統計学:統計学的方法を用いて欠損値補完やスケーリングを行う。
- データクリーニング:人力によってデータをチェックし、誤った値を修正する。
前処理のツール
前処理には様々なツールが使用されます。PythonやRなどのプログラミング言語や、ExcelやTableauなどのデータ分析ソフトウェアなどがあります。各ツールには異なる長所や短所があり、データの特性や分析の目的によって適切なツールを選択する必要があります。
- Python:機械学習や統計学に基づく前処理を行うことができる。
- R:統計学に基づく前処理を行うことができる。
- Excel:データクリーニングやスケーリングを行うことができる。
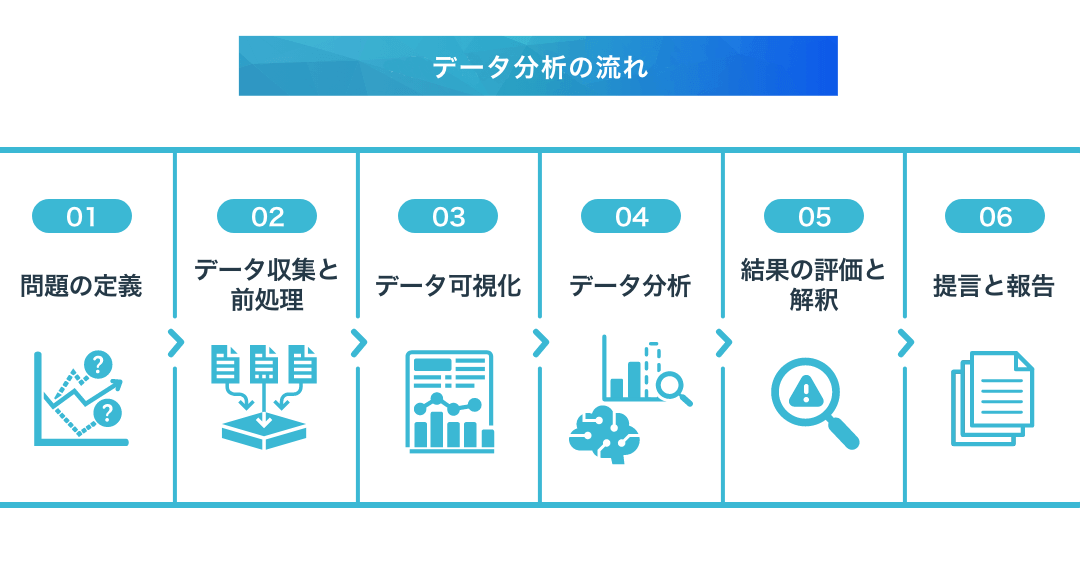
データ分析の5つのステップは?
データ分析の5つのステップは、データを収集、整理、分析、解釈、報告の5つのプロセスで構成されています。
ステップ1: データ収集
データ分析の第一歩は、データの収集です。このステップでは、分析対象となるデータを収集し、保存するための方法やツールを設定します。
- データのソースの特定
- データの形式や構造の決定
- データの収集方法の選択
ステップ2: データ整理
データ整理は、収集されたデータをきれいに整えるプロセスです。このステップでは、データの質を高めるために、欠損値の処理やデータの変換を行います。
- データの質の把握
- 欠損値の処理
- データの変換
ステップ3: データ分析
データ分析は、整理されたデータを分析するプロセスです。このステップでは、統計的分析や機械学習を適用して、資料から洞察を得ます。
- 統計的分析の適用
- 機械学習の適用
- 資料の要約
グレイモデルとはどのような分析方法ですか?
グレイモデルとは、 системаの入出力データから、黒箱モデルを構築し、システムの挙動を把握するための分析方法です。具体的には、システムの入力信号と出力信号の関係をモデル化し、システムの動的挙動やパラメータを推定することを目的としています。
グレイモデルの特徴
グレイモデルの大きな特徴は、システムの機械学的な方程式を必要としないことです。また、ノイズがある場合でも、効果的にモデル化することができます。ただし、グレイモデルの精度は、入出力データの質に依存します。
グレイモデルの種類
グレイモデルには、以下の種類があります。
- GM(1,1): 一つの入力信号と一つの出力信号を持つ最も基本的なグレイモデル
- GM(n,m): nつの入力信号とmつの出力信号を持つグレイモデル
- NGM: 非線形グレイモデルのことを指す
グレイモデルの適用分野
グレイモデルは、工学、経済、生医学などの分野で、システムの分析や予測に広く適用されています。具体的には、品質管理、予測制御、システム同定などの分野でグレイモデルが活用されています。
- 品質管理:製品の品質を予測するためにグレイモデルを適用
- 予測制御:システムの予測制御にグレイモデルを適用
- システム同定:システムのパラメータを推定するためにグレイモデルを適用
モデルの前処理とは?
モデルの前処理とは、機械学習や人工知能でのモデルの性能向上を目的として、実際のデータをモデルに適合させるための手順を指します。その目的は、モデルの汎化性能を高めることによって、将来のデータに対しても高い精度を保持することにあります。
前処理の目的
モデルの前処理の目的は、以下の通りです。
- ノイズの除去:実際のデータにはノイズや誤りが含まれており、これらを除去することでモデルの性能を向上させる。
- データの正規化:異なるスケールのデータを統一することでモデルの学習を促進させる。
- 特徴量の抽出:データ中に含まれる特徴量を抽出することでモデルの性能を向上させる。
前処理の種類
モデルの前処理には、以下のような種類があります。
- スケーリング:データを統一スケールに맞춤ことで、モデルの学習を促進させる。
- NORMALIZATION:データを平均値0、分散1に맞춤ことで、モデルの性能を向上させる。
- FEATURE ENGINEERING:データ中に含まれる特徴量を抽出することでモデルの性能を向上させる。
前処理の重要性
モデルの前処理は、機械学習や人工知能でのモデルの性能向上に非常に重要です。
- モデルの汎化性能向上:モデルの前処理によって、モデルの汎化性能を高めることができる。
- トレーニング時間の短縮:モデルの前処理によって、トレーニング時間を短縮することができる。
- モデルの解釈性向上:モデルの前処理によって、モデルの解釈性を向上させることができる。
よくある質問
データ分析の基礎がある程度理解している人向けは هذهコースを取るべきか?
このコースは、データ分析の基礎にある程度理解している人を対象としており、より詳しく前処理、モデル構築、適用について学ぶことができます。独学や既往の経験による知識では不足している部分を補い、実践的なスキルを身に付けられます。また、データ分析の基礎をより深く理解することで、将来的に更に高度な分析や機械学習に取り組む際の基盤を固めることができます。
このコースで behandeln されるトピックはどのようなものか?
このコースでは、データ分析の基礎から応用までを網羅的にカバーしています。前処理の基本的な概念から、モデル構築の手法やテクニックまでを含み、最後には実際のデータに適用するための実践的なスキルを身に付けられます。また、コース内では、PythonやRなどのデータ分析に必要なツールの使い方も学ぶことができます。
このコースを受講するために必要な前提知識はあるか?
このコースを受講するためには、データ分析や統計学の基礎的な知識がある程度あることが望ましいです。PythonやRの基礎もある程度理解していることが望ましいですが、初心者向けのコースではありません。データ分析の基礎や統計学の基礎的な概念に精通している方がより効果的にコースを進めることができます。
このコースを終了したらどのようなスキルを身に付けられるの?
このコースを終了したら、データ分析の基礎から応用までを包括的に理解できるようになり、実際のデータに適用するための実践的なスキルを身に付けられます。前処理やモデル構築の手法やテクニックを柔軟に適用できるようになり、データ分析の基礎をより深く理解することができます。また、コース内で学んだスキルを基に、将来的には更に高度な分析や機械学習に取り組むことができます。