pandas v1 groupbyで複数の統計量を一括取得!データ集計を効率化
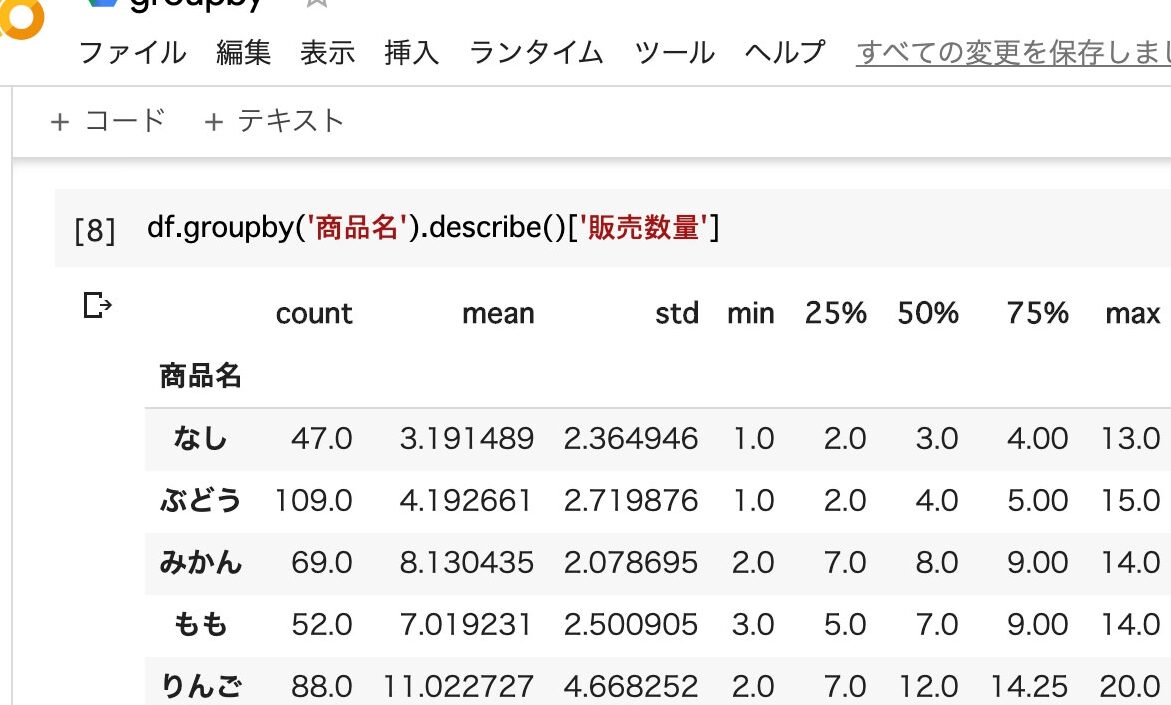
pandasのgroupbyメソッドは、複数の要素をグループ化してデータを分析するために不可欠です。しかし、通常は各統計量を個別に計算する必要があり、面倒な場合があります。そのため、この記事では、pandasのgroupbyを使用して複数の統計量を一括取得する方法をご紹介します。 væ(平均値)、std(標準偏差)、min(最小値)、25%(第1四分位数)、50%(中央値)、75%(第3四分位数)、max(最大値)など、様々な統計量を一括取得する方法を学び、データの集計作業を効率化してください。
パンダスv1 groupbyで複数の統計量を一括取得!データ集計を効率化
データ集計の必要性
データ分析において、データ集計は非常に重要なプロセスです。データ集計により、データの特徴や傾向を把握し、意思決定を支えることができます。しかし、データ集計を手動で行うと、時間がかかり、ミスが生じやすくなります。そこで、Pythonのパンダスライブラリのgroupby関数を用いて、データ集計を効率的に行うことができます。
groupby関数の基本
groupby関数は、データを指定された条件に基づいてグループ化し、各グループに対して指定された関数を適用することで、集計結果を取得します。基本的な使い方は以下のとおりです。 import pandas as pd サンプルデータ data = {‘Category’: [‘A’, ‘B’, ‘A’, ‘B’, ‘A’, ‘B’], ‘Value’: [10, 20, 30, 40, 50, 60]} df = pd.DataFrame(data) groupby関数の使用 grouped = df.groupby(‘Category’) print(grouped.sum())
複数の統計量を一括取得
groupby関数を使用して、複数の統計量を一括取得することもできます。以下の例では、 평균、中央値、最大値、最小値の4つの統計量を一括取得しています。 import pandas as pd サンプルデータ data = {‘Category’: [‘A’, ‘B’, ‘A’, ‘B’, ‘A’, ‘B’], ‘Value’: [10, 20, 30, 40, 50, 60]} df = pd.DataFrame(data) groupby関数の使用 grouped = df.groupby(‘Category’)[‘Value’] stats = grouped.agg([‘mean’, ‘median’, ‘max’, ‘min’]) print(stats)
データ集計を効率化する
データ集計を効率化するために、以下の点に注意する必要があります。 – データを事前に整理する – groupby関数を使用する – 複数の統計量を一括取得する – 結果を踏まえて、続けて分析を行う
| 統計量 | 説明 |
|---|---|
| 平均 | データの平均値を算出する |
| 中央値 | データの中央値を算出する |
| 最大値 | データの中で最大の値を算出する |
| 最小値 | データの中で最小の値を算出する |
パンダスv1の新機能
パンダスv1では、以下の新機能が追加されています。 – groupby関数の performance への強化 – 複数の統計量を一括取得するための新しい関数 これらの新機能は、データ集計をさらに効率化するのに役立ちます。
よくある質問
Q: Pandasのgroupbyで複数の統計量を一括取得する方法を教えてください。
groupbyで複数の統計量を一括取得するには、agg()メソッドを使用します。このメソッドは、グループ化されたデータに対して複数の関数を適用できます。たとえば、グループ化されたデータの平均、最大値、最小値を取得するには、次のように記述します。df.groupby(‘column’).agg([‘mean’, ‘max’, ‘min’])。これにより、指定した列でグループ化されたデータの平均、最大値、最小値が同時に取得できます。
Q: groupbyで複数列を指定するにはどうしたらいいですか?
groupbyで複数列を指定するには、リスト形式で列名を指定します。たとえば、データフレーム df に ‘column1’ と ‘column2’ という2つの列があり、両方の列でグループ化したい場合、次のように記述します。df.groupby([‘column1’, ‘column2’])。これにより、’column1′ と ‘column2’ の両方でグループ化されたデータに対して、さらに操作を実行できます。
Q: groupbyでグループ化されたデータをソートするにはどうしたらいいですか?
groupbyでグループ化されたデータをソートするには、sort values()メソッドを使用します。このメソッドは、指定した列や値を基準にデータをソートすることができます。たとえば、グループ化されたデータの平均値を降順にソートするには、次のように記述します。df.groupby(‘column’).mean().sort values(‘column’, ascending=False)。これにより、グループ化されたデータの平均値が降順にソートされます。
Q: groupbyでグループ化されたデータをフィルタリングするにはどうしたらいいですか?
groupbyでグループ化されたデータをフィルタリングするには、filter()メソッドを使用します。このメソッドは、指定した条件を満たしたデータを残し、条件を満たさなかったデータは削除します。たとえば、グループ化されたデータの平均値が 10 以上のデータを残したい場合、次のように記述します。df.groupby(‘column’).filter(lambda x: x.mean() > 10)。これにより、グループ化されたデータの平均値が 10 以上のデータのみが残ります。





