R:重回帰分析で交差項を考慮!より高度な分析に挑戦
統計分析において、重回帰分析は IData の相関関係を捉えるための有効的な手法です。しかし、単に重回帰分析を行うだけでは、複雑な相関関係にある交差項の影響を捉えることができません。本稿では、重回帰分析に交差項を考慮入れた分析手法を紹介し、高度なデータ分析に挑戦します。交差項を適切にモデル化することで、より精度の高い予測や解析結果を得ることができます。本稿を通じて、データ分析の新たな可能性を広げていきましょう。

R:重回帰分析で交差項を考慮!より高度な分析に挑戦
重回帰分析は、統計分析の基本的な手法の一つである。ただし、交差項を考慮しないと、分析結果が誤っていく可能性がある。そこで、本稿では、Rを用いて重回帰分析で交差項を考慮する方法について説明する。
交差項とは
交差項とは、2つの独立変ouserが相互に関係している場合に生じる効果のことである。例えば、学習者の性別と学習時間が、成績に対してどのように影響しているのかを調べる場合、性別と学習時間の交差項を考慮する必要がある。
| 独立変数 | 相互作用の効果 |
|---|---|
| 性別 | 成績に対する性別の効果 |
| 学習時間 | 成績に対する学習時間の効果 |
| 性別×学習時間 | 性別と学習時間の交差項の効果 |
Rでの交差項の指定
Rでは、交差項を指定するには、“や`:`を用いる。例えば、`lm(y ~ x1 x2)`では、x1とx2の交差項を考慮している。 y ~ x1 x2:x1とx2の交差項を考慮
交差項の効果の検定
交差項の効果を検定するには、ANOVAを用いる。Rでは、`anova()`関数を用いて、交差項の効果を検定することができる。 anova():交差項の効果を検定
交差項の可視化
交差項の効果を可視化するには、Interaction Plotを用いる。Rでは、`interplot()`関数を用いて、交差項の効果を可視化することができる。 interplot():交差項の効果を可視化
交差項の注意点
交差項を考慮する際には、注意点がある。例えば、交差項の多さにより、モデルが過剰になりうるため、注意してモデルの設定を行う必要がある。 注意点:交差項の多さによるモデル過剰
重回帰分析の弱点は何ですか?

多重共線性の問題
重回帰分析の弱点の一つに、多重共線性の問題があります。多重共線性とは、独立変数間に強い相関関係がある状態を指します。この状態では、モデルの信頼性が低下し、推定結果が不確実になる可能性があります。例えば、สองつの独立変数が非常に強い相関関係にある場合、それらの変数の効果を確実に捉えることができない可能性があります。
- 多重共線性の検出:共分散行列や相関係数行列を用いて、多重共線性を検出します。
- 多重共線性の対処:独立変数の選択や、 Dimensionality Reduction などの方法を用いて、多重共線性を緩和します。
- 多重共線性の影響:モデルの信頼性や推定結果に与える影響を評価し、適切に対処します。
過学習の問題
重回帰分析の弱点の一つに、過学習の問題があります。過学習とは、モデルの複雑さが高すぎて、訓練データに過度に適合する状態を指します。この状態では、モデルが汎化性能を失い、新しいデータに対する予測性能が低下する可能性があります。
- 過学習の検出:訓練誤差と検証誤差を比較し、過学習を検出します。
- 過学習の対処:Regularization などの方法を用いて、モデルの複雑さを制限します。
- 過学習の影響:モデルの汎化性能や予測性能に与える影響を評価し、適切に対処します。
データの欠けやノイズの影響
重回帰分析の弱点の一つに、データの欠けやノイズの影響があります。データの欠けやノイズがあると、モデルが誤った推定結果を生み出す可能性があります。この状態では、モデルの信頼性が低下し、推定結果が不確実になる可能性があります。
- データの欠けやノイズの検出:データの分布やグラフを用いて、データの欠けやノイズを検出します。
- データの欠けやノイズの対処:データの補完やノイズ除去などの方法を用いて、データの質を改善します。
- データの欠けやノイズの影響:モデルの信頼性や推定結果に与える影響を評価し、適切に対処します。
重回帰分析の目的は何ですか?
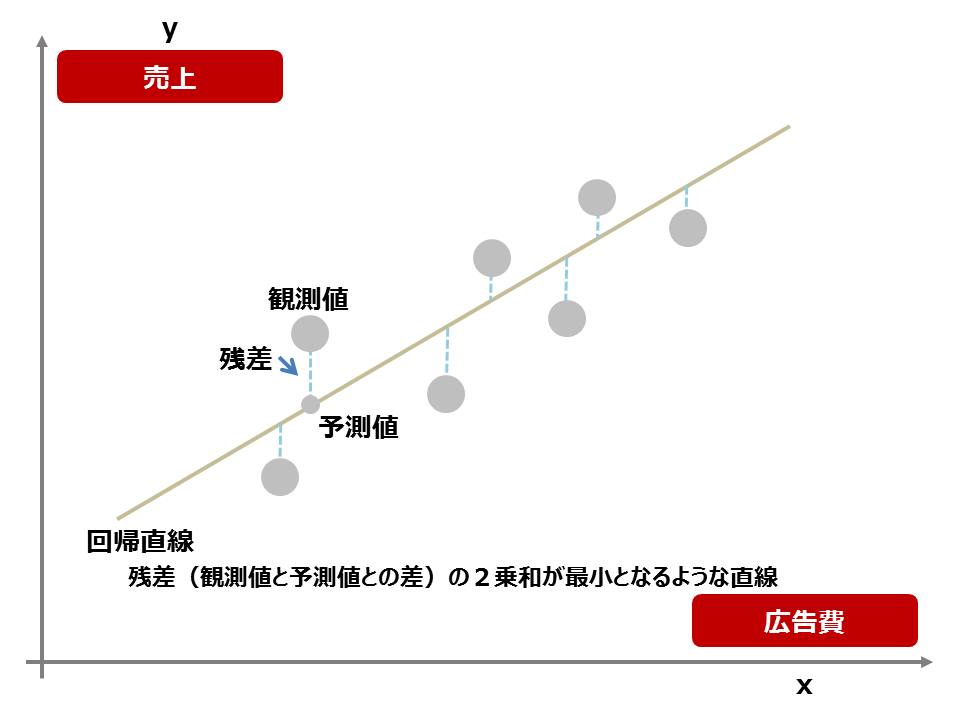
重回帰分析の目的は、何ですか?
重回帰分析は、複数の独立変数が依存変数に与える影響を検討するために行います。那たちは、個々の独立変数の影響を把握し、同時に他の独立変数の影響を調整することで、より正確な予測モデルを構築することを目指しています。
関係係数の推定
重回帰分析の目的の一つは、関係係数の推定です。関係係数とは、独立変数と依存変数の間に存在する相関관계の強さを示す値です。重回帰分析を行うことで、個々の独立変数の関係係数を推 Mahmudし、予測モデルの正確さを高めることができます。
- 関係係数の推定には、標準化係数や偏OLS係数を用います。
- これらの係数を用いることで、独立変数の影響力を正確に把握できます。
- 結果として、予測モデルの正確さが高まります。
影響の相互作用の検討
重回帰分析の目的の一つは、影響の相互作用を検討することです。個々の独立変数が依存変数に与える影響には、相互作用が存在することがあります。重回帰分析を行うことで、この相互作用を検討し、予測モデルの正確さを高めることができます。
- 相互作用の検討には、交互作用項を導入します。
- 交互作用項を用いることで、独立変数の相互作用を把握できます。
- 結果として、予測モデルの正確さが高まります。
予測モデルの構築
重回帰分析の目的の一つは、予測モデルの構築です。重回帰分析を行うことで、個々の独立変数の影響を把握し、予測モデルを構築することができます。その結果、将来のデータに対する予測をより正確に行うことができます。
- 予測モデルの構築には、重回帰方程式を用います。
- 重回帰方程式を用いることで、個々の独立変数の影響を把握できます。
- 結果として、予測モデルの正確さが高まります。
回帰分析の欠点は何ですか?
回帰分析は、統計学において広く用いられている手法ですが、いくつかの欠点があります。以下は、回帰分析の欠点の一部です。
過学習の問題
回帰分析において、モデルの複雑さが増すにつれ、過学習の問題が生じます。過学習とは、訓練データに過度に適合することで、モデルが nieuwe データに対応できなくなる現象です。過学習の問題により、モデルが generalization性能を失い、実際の予測性能が低下します。
- 訓練データのノイズに影響を受ける
- モデルが複雑になるにつれ過学習の可能性が高まる
- 過学習を避けるために、モデルの複雑さを制限する必要がある
仮定の誤り
回帰分析において、仮定の誤りが生じます。線形性の仮定や独立同分布の仮定など、仮定が満たされていない場合、モデルが正しく機能しない可能性があります。また、仮定の誤りにより、モデルが不正確な結果を生み出すことになります。
- 線形性の仮定が満たされていない場合、非線形回帰分析を使用する必要がある
- 独立同分布の仮定が満たされていない場合、異常値の処理が必要になる
- 仮定の誤りを避けるために、データを cuidadosamente 調べる必要がある
説明変数の選択
回帰分析において、説明変数の選択が重要です。重要な説明変数を選択しないと、モデルが不正確になる可能性があります。また、不要な説明変数を選択すると、モデルが複雑になる可能性があります。
- 重要な説明変数を選択するために、前処理が必要になる
- 不要な説明変数を選択すると、モデルが過学習になる可能性がある
- 説明変数の選択には、ドメイン知識が必要になる
重回帰分析における標準誤差とは?
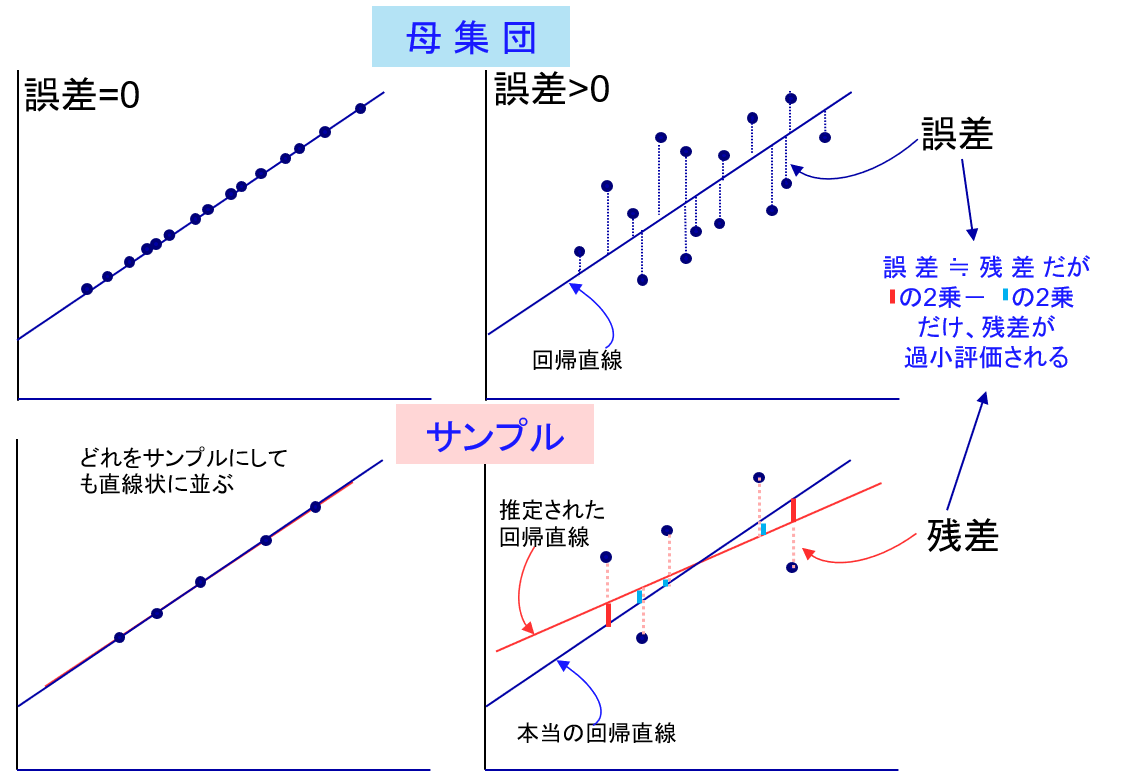
重回帰分析における標準誤差とは、各係数の推定値に対する信頼度を示す統計量です。標準誤差は、標本のサイズやデータのばらつきに依存するため、係数の推定値が真の値からどれだけ乖離しているかを示唆します。
標準誤差の計算方法
標準誤差の計算方法はいくつかありますが、最も一般的なのは、最大尤度推定による方法です。この方法では、標本のデータに基づいて、モデルパラメーターの尤度関数を最大化する値を計算します。計算結果は、標準誤差に対応する値としてufigに用いられます。
- 標本のデータを基に、モデルパラメーターの尤度関数を計算する。
- 尤度関数を最大化する値を計算する。
- 計算結果を標準誤差として使用する。
標準誤差の意味
標準誤差は、係数の推定値が真の値からどれだけ乖離しているかを示唆します。小さい標準誤差は、係数の推定値が真の値に近いことを示し、大きい標準誤差は、係数の推定値が真の値から乖離していることを示します。
- 小さい標準誤差:係数の推定値が真の値に近い。
- 大きい標準誤差:係数の推定値が真の値から乖離している。
- 標準誤差が大きい場合、係数の推定値には注意が必要である。
標準誤差の利用
標準誤差は、係数の推定値に対する信頼度を示すため、統計的推測や予測モデルの評価に利用されます。標準誤差の小さい係数は、真の値に近いと考えられ、標準誤差の大きい係数は、注意が必要であると考えられます。
- 標準誤差の小さい係数:真の値に近いと考えられる。
- 標準誤差の大きい係数:注意が必要であると考えられる。
- 標準誤差を基に、係数の推定値に対する信頼度を評価する。
よくある質問
R:重回帰分析における交差項の効果がいかに大きな影響を与えるのか。
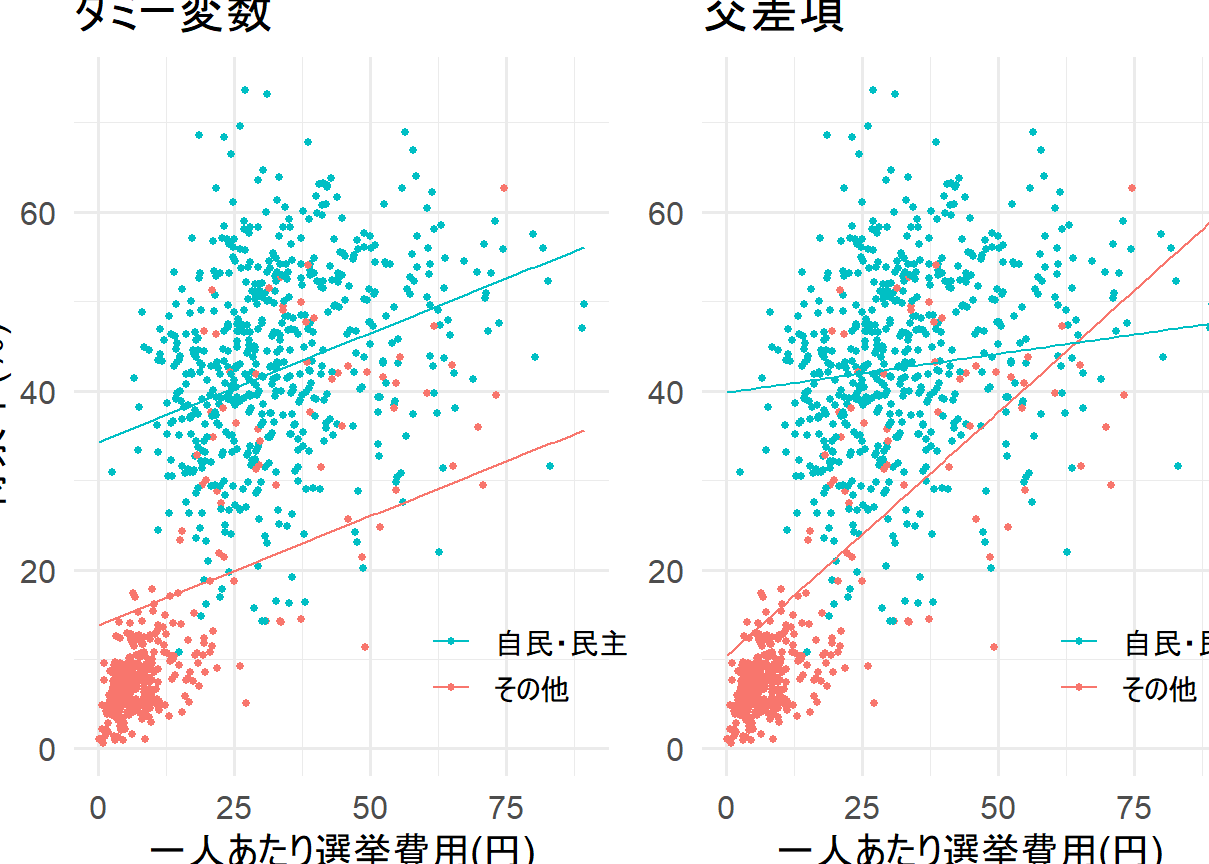
交差項を導入することで、モデル精度が向上し、予測性能も高まることが期待できます。交差項がなければ、独立変数同士の関係性を捉えることができないため、モデルの推定が不正確になる場合があります。交差項を使用することで、相互作用の効果を捉えることができ、より正確な予測を行うことができます。
重回帰分析における交差項の導入方法は何か。
交差項を導入する方法はいくつかあります。相互作用項を導入する方法がいちばん簡単です。例えば、A変数とB変数の交差項を導入するには、A変数とB変数の積を計算し、新たな独立変数として追加します。非線形相互作用を捉えるには、多項式回帰やスプライン回帰などの方法を使用することができます。
交差項の導入によるモデルの複雑さが問題になることはないのか。
交差項を導入することで、モデル複雑さが増加します。これにより、過学習の問題が生じる場合があります。ただし、モデル選択や検定によって、最適なモデルを選択することができます。交差項を導入することで、モデル精度が向上する場合がある一方で、過学習に陥る場合もないとは限りません。したがって、モデル構築には十分な注意を払う必要があります。
Rでの重回帰分析における交差項の実装方法は何か。
Rでは、lm()関数を使用して交差項を導入することができます。例えば、A変数とB変数の交差項を導入するには、`lm(Y ~ A B, data = df)`のように記述します。交差項を導入することで、モデル推定を行うことができます。Rでは、交差項の検定もanova()関数を使用して行うことができます。