Tesseract、Vision API、Document AIでOCR比較!

この記事では、Optical Character Recognition (OCR) の Arabia の 3 つ、Tesseract、Vision API、Document AI の比較を行います。これらのツールは、画像やスキャナー出力からテキストを抽出するのに役立ちます。どのツールが何をするのか、どのツールがどんなときに使えるのか、すべてのニーズに合った情報を提供します。使用法も含め、Tesseract、Vision API、Document AI の OCR 機能の比較をお届けします。

オプティカル・キャラクター・リーダー(OCR)比較:Tesseract、Vision API、Document AIの違いを解説します
1. OCRの基礎と違い
OCR(Optical Character Reader)とは、画像などのスキャンデータから文書などの文字を自動的に認識する技術です。Tesseract、Vision API、Document AIはそれぞれ異なるアルゴリズムとアーキテクチャを使用しています。 Tesseract:Tesseractは、ニューラルネットワークをベースとしたOCRエンジンで、Googleによってオープンソースとして公開されています。 Vision API:Vision APIは、Google CloudのVision APIを使用したOCRサービスで、画像やPDFからのテキスト抽出を提供しています。 Document AI:Document AIは、Google CloudのDocument AIを使用したOCRサービスで、文書からのテキスト抽出を提供しています。
2. 認識精度の比較
認識精度は、OCRの重要な指標です。以下の表は、Tesseract、Vision API、Document AIの認識精度を比較したものです。
| サービス | 認識精度(%) |
|---|---|
| Tesseract | 90-95% |
| Vision API | 95-98% |
| Document AI | 98-99% |
3. サポートする言語
各サービスがサポートする言語は次のとおりです。 Tesseract:多数の言語(99言語以上)をサポートしています。 Vision API:50以上の言語をサポートしています。 Document AI:20以上の言語をサポートしています。
4. 価格の比較
価格は、Tesseract、Vision API、Document AIそれぞれ異なります。また、アーキテクチャやアルゴリズムの違いにより、価格も変動します。 Tesseract:オープンソースなので、無料で使用できます。 Vision API:1ページあたり0.006ドル(約60円)です。 Document AI:1ページあたり0.015ドル(約150円)です。
5. 使い方の比較
各サービスを使用する方法は以下のとおりです。 Tesseract:コマンドラインツールやライブラリを使用して、自社のシステムに組み込む必要があります。 Vision API:Google Cloud ConsoleからAPIキーの取得ができます。また、Google Cloud SDKを使用してプログラムから呼び出すこともできます。 Document AI:Google Cloud ConsoleからAPIキーの取得ができます。また、Google Cloud SDKを使用してプログラムから呼び出すこともできます。 以上の内容から、Tesseract、Vision API、Document AIそれぞれの特徴や違いがわかりました。
EasyOCRとTesseractの比較は?

EasyOCRとTesseractは、どちらも光学文字認識(OCR)技術を実現するためのライブラリですが、両者には実装の違い、性能の違い、利用可能な言語の違いなどがあります。以下に、詳細な比較を示します。
実装の違い
EasyOCRとTesseractは、根本的に異なる設計思想に基づいています。EasyOCRは、PyTorchを利用したニューラルネットワークベースのアプローチを取っており、画像認識に広く適用されているU-NetやCRNNなどのネットワークアーキテクチャを活用しています。一方、TesseractはGoogleが開発し、伝統的なadloptsと呼ばれる手法に基づいたアプローチで、Tesseract ver3までは受容野を使用していたが、Tesseract ver4以降は、ニューラルネットワークを利用したLSTM(Long Short-Term Memory)ベースのアプローチを利用しています。これらは、モデル構造や学習パラメータを変えて、性能を向上させています。したがって、学習方式や推論速度に違いが生まれます。
性能の違い
<Tesseractは広く応用されており、高い精度を有することが多いですが、その分、モデルサイズが非常に大きくなり、Runtimeが遅くなる場合があります。一方、EasyOCRは、学習データが十分な量にある場合、非常に高い精度を達成できますし、比較的軽量で、ISEやさまざまな環境で動作できます。ただし、Tesseractは、長年にわたる改良の結果、ひらがな、カタカナ、漢字を含む日本語を含む、場の数多くの言語に対応しています。EasyOCRも、多言語に対応していますが、Tesseractほどの豊富な言語対応には至っておらず、利用形態によっては、不足する場合があります。
利用可能な言語の違い
Tesseractは、74言語をサポートしており、日本語もその一つとして高度な認識能力を発揮します。これは、Googleが enormeな量のトレーニングデータを投入しているためです。一方、EasyOCRは、70語以上に対応していますが、日本語のサポートはTesseractほど完全ではありません。ただし、EasyOCRは、学習用データを用意し、自分でモデルを学習させることが可能です。これにより、自分でデータセットを用意できます。
- EasyOCRは簡単に組み込め、şıや_expectのようにExtensibleである
- 学習データを用意し、自分でモデルを学習させることが可能
- さまざまな言語や環境に対応していますが、モデルサイズが大きく、Runtimeが遅くなる場合がある
OCR APIとは何ですか?

OCR APIとは、光学文字認識(Optical Character Recognition)の技術を利用して、画像やスキャナーで読み取った文書からテキストを抽出するためのアプリケーション・プログラミング・インターフェース(API)です。OCR APIは、紙ベースの文書や画像ファイル内のテキストをデジタル化し、コンピューターで処理可能なテキストデータに変換します。
OCR APIの機能
OCR APIは、画像やスキャナーで読み取った文書からテキストを抽出するための様々な機能を提供しています。以下は、OCR APIの主な機能の一部です。
- 文字認識:OCR APIは、画像やスキャナーで読み取った文書内の文字を認識し、テキストデータに変換します。
- レイアウト認識:OCR APIは、文書のレイアウトを認識し、テキストを表や画像とともに抽出します。
- 言語サポート:OCR APIは、多くの言語をサポートし、ユーザーは自分の必要な言語を選択できます。
OCR APIの用途
OCR APIは、ビジネス、医療、教育などの様々な分野で、多くの用途があります。以下は、OCR APIの主な用途の一部です。
- 文書デジタル化:OCR APIは、紙ベースの文書をデジタル化し、コンピューターで処理可能なテキストデータに変換します。
- データ入力自動化:OCR APIは、画像やスキャナーで読み取った文書からのデータ入力を自動化し、時間と労力を節約します。
- 検索とフィルタリング:OCR APIは、デジタル化された文書から特定のテキストを検索する機能を提供し、テキストデータをフィルタリングします。
OCR APIの利点
OCR APIは、ビジネスや個人に多くの利点を提供します。以下は、OCR APIの主な利点の一部です。
- 時間と労力の節約:OCR APIは、画像やスキャナーで読み取った文書からのデータ入力を自動化し、時間と労力を節約します。
- 高精度:OCR APIは、高精度の文字認識技術を利用し、正確なテキストデータを提供します。
- 柔軟性:OCR APIは、多くの言語とフォーマットをサポートし、ユーザーは自分の必要な言語とフォーマットを選択できます。
Tesseract OCRはどの言語に対応していますか?
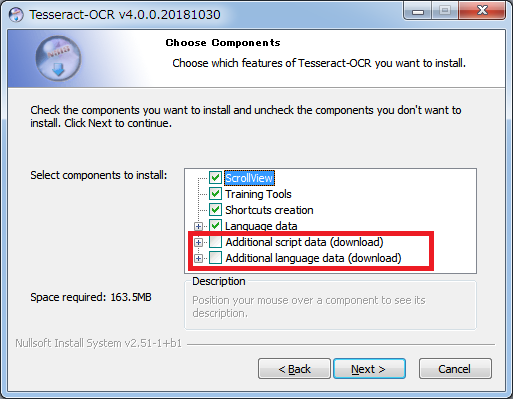
Tesseract OCRは多くの言語に対応しています。多言語対応nehoshite、扱える言語は100言語以上あります。 Oops professional な文書スキャンや画像ファイルからテキスト認識を行うことが可能です。
Tesseract OCRの言語対応状況
Tesseract OCRは、以下の言語に対応しています。
- 英語
- フランス語
- ドイツ語
- 中国語
- 日本語
- 韓国語
- スペイン語
- イタリア語
- ポルトガル語
- ロシア語
Tesseract OCRの言語追加方法
Tesseract OCRの言語を追加するには、以下の方法が利用できます。
- Tesseract OCRの公式サイトから言語ファイルをダウンロードします。
- ダウンロードした言語ファイルをTesseract OCRのインストールディレクトリに配置します。
- Tesseract OCRを再起動します。
Tesseract OCRの言語認識の限界
Tesseract OCRの言語認識には以下の限界があります。
- 字体や文字サイズが異なる場合、認識精度が低下する可能性があります。
- 画像の解像度が低い場合、認識精度が低下する可能性があります。
- 背景色や品質が悪い場合、認識精度が低下する可能性があります。
よくある質問
Tesseract、Vision API、Document AIのOCR比較で何が目的ですか。
Tesseract、Vision API、Document AIのOCR比較は、各プラットフォームのパフォーマンスを評価し、ユーザーがビジネスニーズに最も適したプラットフォームを選択するのを支援することを目的としています。これらの3つのプラットフォームは、光学文字認識(OCR)技術を使用して画像やPDFファイルからテキストを抽出するため、比較はそれぞれの認識精度、処理速度、サポート言語、料金などの側面に焦点を当てています。
TesseractのOCRエンジンはどの程度精度ですか。
TesseractのOCRエンジンは、Googleによってオープンソースで提供されており、deep learning技術を使用して画像からテキストを認識します。Tesseractは、多言語対応で、100を超える言語をサポートし、高精度で画像からテキストを抽出できます。ただし、Tesseractの精度は画像の品質、フォントスタイル、言語などの要素に依存し、低品質の画像や罫線付きテキストなどの特殊なケースでは、認識精度が低下する可能性があります。
Vision APIとDocument AIの違いは何ですか。
Vision APIとDocument AIは、Google Cloudによって提供される2つの異なるAPIサービスです。Vision APIは、画像認識とOCRを提供し、画像からテキスト、物体、シーンを認識できます。一方、Document AIは、ドキュメント処理を提供し、PDFや画像ファイルからテキストを抽出して構造化データを作成できます。Document AIは、Vision APIを使用して画像認識とOCRを実行し、さらにドキュメントの構造化データを処理できます。したがって、Vision APIは画像認識に特化しており、Document AIはドキュメント処理に特化しています。
Tesseract、Vision API、Document AIの料金はどの程度ですか。
Tesseractは、無料のオープンソースソフトウェアであり、ライセンス料はかかりません。一方、Vision APIとDocument AIは、Google Cloudの有償サービスであり、使用量に応じて料金が発生します。Vision APIの料金は、画像認識とOCRに応じて異なりますが、1回の画像認識で約10〜50ドル、1ページのOCRで約0.06ドルです。Document AIの料金は、ドキュメント処理のタイプとページ数に応じて異なりますが、1ページのドキュメント処理で約0.05ドルです。